Build shape
Civic-data service plus OCR research
Civic data and OCR research tool
A project that combined civic-data product work with Korean OCR research, backed by APIs and internal tooling.
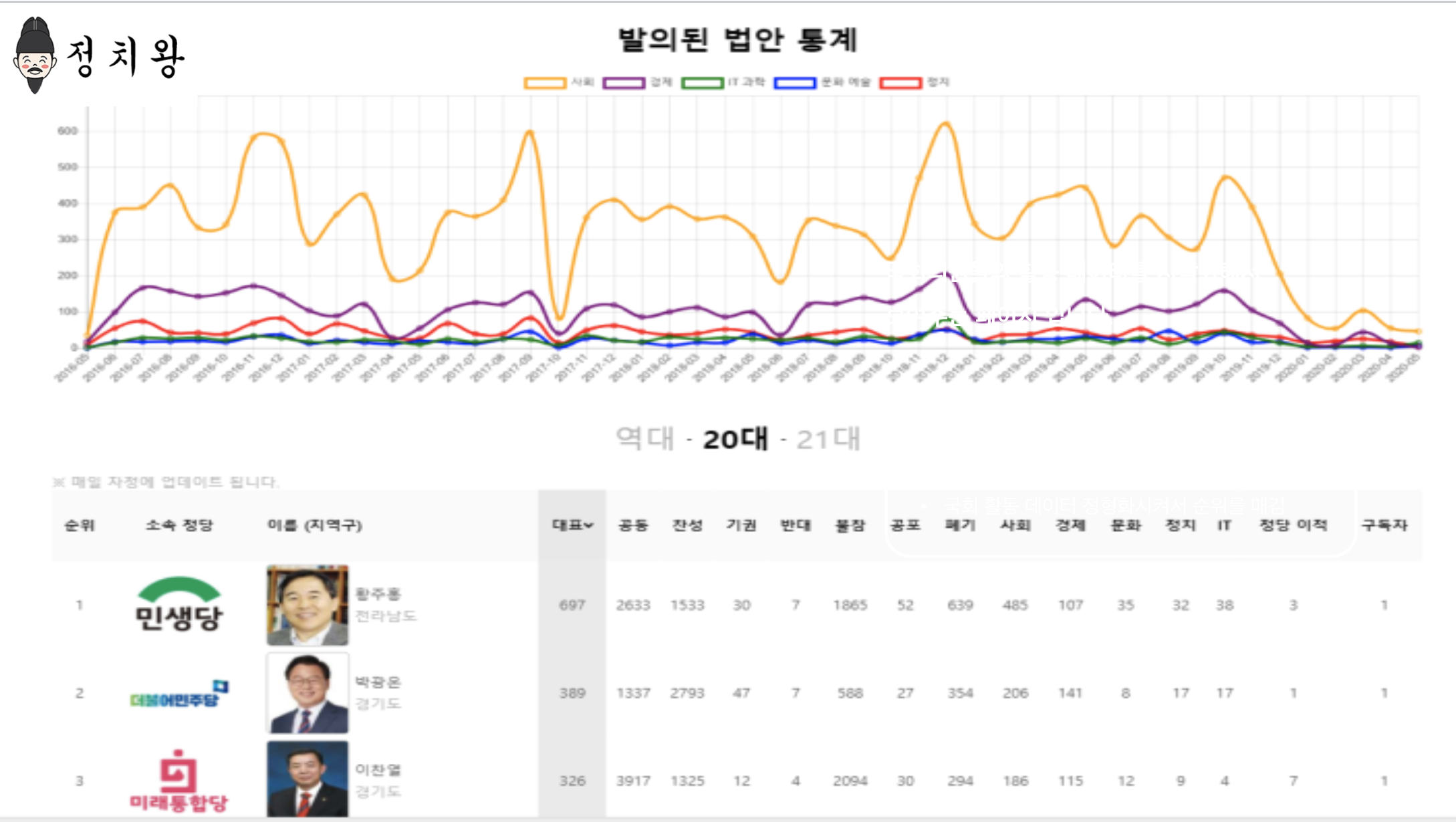
Product brief
Politics King and OCR R&D comes from a period where civic-data product work and Korean OCR research were being carried in parallel. The product side needed crawlers, APIs, and dashboard views, while the research side needed repeatable test-bed tooling and evaluation loops.
In the implemented scope, a Node.js API layer, Python-based crawlers, a statistics dashboard, Korean OCR benchmarking tools, and internal utilities were built together. It is an early project that shows service data work and research tooling in the same environment.
Scope
Problem
Political and bill data kept changing, and OCR research needed repeated evaluation, so collection and verification both had to be automated.
Implementation
I built the Node.js API layer, crawlers, a stats dashboard, a Korean OCR testbed, and internal tools directly.
Best fit
This fits data products and research environments that need crawling, internal analytics, and repeatable evaluation tooling together.
Technical structure
Build shape
Civic-data service plus OCR research
Primary stack
Node.js · Python · crawler · dashboard
Data & sync
Automated politician/bill collection · stats visualization
Operational surface
OCR testbed · internal tooling · API operations
Screens
Web
Send the current problem, scope, or a reference link. The next step can start from product structure and release scope.